Ein Schadensfall landet auf dem Tisch. Ein Kunde meldet einen Autounfall. Alles wirkt plausibel: Unterlagen vollständig, Ablauf nachvollziehbar, keine auffälligen Hinweise. Der Fall wird geprüft, freigegeben und abgeschlossen.
Genau in diesem Moment beginnt der Blindflug, ohne dass es jemand bemerkt. Wer denkt schon darüber nach, dass ein scheinbar normaler Fall Teil eines größeren Betrugmusters sein könnte?
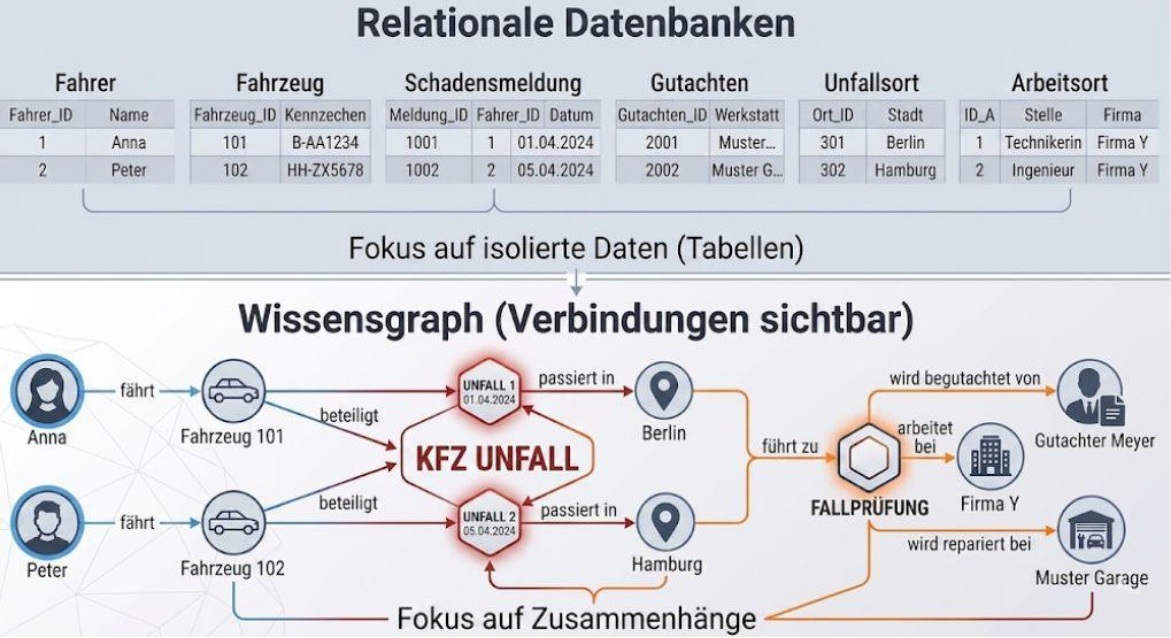
Ein paar Tage später meldet ein anderer Kunde einen ähnlichen Unfall: wieder ein Auto, wieder alles scheint normal. Würde man die Fälle unabhängig voneinander betrachten, wirkt jeder einzelne harmlos. Doch bei genauerem Hinsehen fallen kleine Auffälligkeiten auf: dieselbe Werkstatt wird erneut eingeschaltet, ein Gutachter taucht auffällig oft auf und es lassen sich feine Verbindungen zwischen den Kunden erkennen, zum Beispiel dieselbe Arbeitsfirma oder gemeinsame Kontakte (siehe Grafik).
Erst wenn man all diese einzelnen Ereignisse zusammendenkt, wird das größere Bild sichtbar: ein wiederkehrendes Betrugsszenario, das sonst unbemerkt geblieben wäre.
Die zentrale Herausforderung besteht darin, vorhandene Informationen intelligent miteinander zu verknüpfen. Versicherer verfügen bereits über umfangreiche Datenbestände, von Kundendetails über Verträge bis hin zu Schadensmeldungen und Interaktionen. Das Problem liegt daher nicht im Mangel an Informationen, sondern darin, sie richtig zu interpretieren und in Zusammenhang zu bringen.
Ohne einen ganzheitlichen Blick bleiben entscheidende Hinweise verborgen. Reaktionen erfolgen isoliert und häufig zu spät, um Betrug frühzeitig zu erkennen und wirksam zu verhindern.
Vom Einzelfall zum Muster - Wie wir Informationen besser verarbeiten können
Solange jeder Schaden einzeln geprüft wird, bleiben die entscheidenden Zusammenhänge unsichtbar. In der Praxis werden Fälle heute oft entlang von Dokumenten, Checklisten und Einzelfallbewertungen bearbeitet. Auffälligkeiten werden manuell erkannt oder über einfache Regeln und Scores in Tabellen abgebildet. Das funktioniert bei klaren Fällen, stößt aber schnell an Grenzen, sobald sich Betrug über mehrere Akteure und Ereignisse hinweg erstreckt.
Genau hier setzen Wissensgraphen an. Sie betrachten Daten nicht isoliert, sondern als Netzwerk aus miteinander verbundenen Elementen. Diese Elemente, sogenannte Entitäten, sind zum Beispiel ein Kunde, ein Fahrzeug, eine Werkstatt oder ein Gutachter. Statt sie nur als einzelne Datensätze zu erfassen, werden sie als Knoten miteinander verknüpft. So wird sichtbar, wer mit wem in Verbindung steht, wie häufig bestimmte Akteure gemeinsam auftreten und welche Strukturen sich über mehrere Fälle hinweg entwickeln (siehe Grafik).
Auf dieser Grundlage lassen sich Muster automatisch erkennen, Zusammenhänge analysieren und Auffälligkeiten im Kontext bewerten. Statt nur einzelne Schäden zu prüfen, wird das gesamte Netzwerk betrachtet.
Für die Praxis bedeutet das konkret: Was vorher wie einzelne, unauffällige Unfälle aussah, wird nun als wiederkehrendes Muster erkennbar. Versicherer können frühzeitig reagieren, Betrugsrisiken reduzieren und fundierte Entscheidungen treffen. Ähnlich vorstellbar wie die Arbeit mit ChatGPT, nur dass die Blackbox mit Wissensgraphen transparent wird und keine überraschenden Fehler mehr gemacht werden, weil die Daten aus dem eigenen Datenbanksystem stammen.
Warum es in der Praxis oft trotzdem scheitert
Die Idee, Zusammenhänge zwischen Schadensfällen sichtbar zu machen, ist nicht neu. Viele Versicherer haben entsprechende Ansätze bereits getestet oder in einzelnen Projekten im Einsatz. In der Praxis zeigt sich jedoch: Der flächendeckende Einsatz ist schwieriger als gedacht.
Ein Grund dafür liegt in den bestehenden Systemen. Daten entstehen in unterschiedlichen Anwendungen wie Schadenbearbeitung, Vertragsverwaltung, Kundenservice oder bei externen Partnern. Diese Systeme funktionieren jeweils gut für ihren eigenen Zweck, aber die Informationen passen nicht automatisch zusammen. Daten zusammenzuführen bedeutet deshalb oft zusätzlichen Aufwand: Sie liegen zum Beispiel in Tabellen oder unterschiedlichen Systemen, sind verteilt und müssen erst miteinander verbunden werden.
Damit daraus ein nutzbares Gesamtbild entsteht, müssen Verknüpfungen aktiv hergestellt werden. Wer gehört zu wem? Welche Akteure tauchen wiederholt gemeinsam auf? Solche Beziehungen sind nicht automatisch vorhanden, sondern müssen definiert und gepflegt werden. Das kostet Zeit und führt in der Praxis häufig dazu, dass nur ein Teil der möglichen Zusammenhänge tatsächlich genutzt wird.
Auch die Auswertung selbst wird mit zunehmender Vernetzung anspruchsvoller. Je mehr Verbindungen berücksichtigt werden müssen, desto schwieriger wird es, den Überblick zu behalten. Besonders bei Betrugsfällen, die sich über mehrere Beteiligte und viele einzelne Ereignisse erstrecken, wird es schnell unübersichtlich.
Genau an diesem Punkt setzen moderne Graphtechnologien an. Sie verändern den Blick auf Daten grundlegend: weg von einzelnen Einträgen hin zu einem zusammenhängenden Netzwerk. Es gibt verschiedene Ansätze, um solche Netzwerke auszuwerten, die sich jedoch in der Praxis oft in Geschwindigkeit und Skalierbarkeit unterscheiden.
Tentris geht hier einen entscheidenden Schritt weiter. Statt Verbindungen einzeln nacheinander zu prüfen, wird das gesamte Netzwerk direkt in einem Durchgang ausgewertet. Dadurch lassen sich auch sehr komplexe Zusammenhänge effizient auswerten, selbst wenn die Datenmengen stark wachsen.
Im Vergleich zu anderen Ansätzen führt das zu deutlich schnelleren Ergebnissen und einer stabilen Verarbeitung auch bei hoher Datenlast.
Das bringt drei klare Vorteile für den Arbeitsalltag:
Millisekunden statt Minuten: Auch sehr komplexe Verbindungen über viele Zwischenstationen hinweg werden sofort sichtbar. Was früher lange Analysen gebraucht hat, steht jetzt in Echtzeit zur Verfügung.
Stabilität bei großen Datenmengen: Das System bleibt auch dann schnell, wenn die Datenbestände wachsen. Millionen von Verträgen, Adressen und Schadensfällen verändern die Performance nicht grundlegend.
Wirtschaftlichkeit durch gezielte Datenverarbeitung: Moderne KI-Systeme arbeiten oft mit sogenannten Tokens, also einzelnen Informationseinheiten. Wenn große, unstrukturierte Datenmengen an die KI gegeben werden, steigen die Kosten schnell an. Hier setzen Graphsysteme an: Sie liefern nur die wirklich relevanten Informationen weiter. Das spart bis zu 97 % dieser Rechenkosten ein und macht den großflächigen Einsatz von KI erst wirklich wirtschaftlich rentabel.
Am Ende: der klare Mehrwert
Wer die Muster erkennt, kann Betrugsversuche früh stoppen, echte Schäden schneller bearbeiten und Kunden gezielter betreuen. Wer nur Einzelfälle betrachtet, reagiert. Wer Muster sieht, handelt.
Nicht die Daten allein machen den Unterschied, sondern das Verständnis dafür, wie sie zusammenhängen. Denn wer Zusammenhänge versteht, verhindert Schäden, erkennt Chancen und verschafft sich so einen klaren Vorteil im Wettbewerb.
Und mal ehrlich: Wer will schon im Blindflug entscheiden, wenn er mit wenigen Klicks die ganze Geschichte sehen könnte?
Ansprechpartner:
Tobias Rebert
Co-Founder, Tentris
E-Mail: tobias@tentris.io
LinkedIn https://www.linkedin.com/in/tobias-rebert
Tentris GmbH
Leopoldstraße 2–8
32051 Herford
Deutschland
https://tentris.io/
Über Tentris
Tentris ist ein Technologieunternehmen, das sich auf die Verarbeitung und Analyse stark vernetzter Daten spezialisiert hat. Im Mittelpunkt steht dabei die Idee, komplexe Daten nicht nur zu speichern, sondern ihre Zusammenhänge direkt nutzbar zu machen. Dafür entwickelt das Unternehmen eigene Graphdatenbank-Technologien, die darauf ausgelegt sind, große und heterogene Datenbestände effizient zu verarbeiten und in Echtzeit auswertbar zu machen. Ziel ist es, Organisationen dabei zu unterstützen, schneller aus Daten Erkenntnisse zu gewinnen und fundierte Entscheidungen zu treffen. Damit positioniert sich Tentris als Infrastruktur für moderne daten- und KI-getriebene Anwendungen.








